EPISODE · Dec 29, 2025 · 37 MIN
a media-almost-archaeology on data that is too dirty for "AI" (39c3)
from Chaos Computer Club - recent events feed (high quality) · host jiawen uffline
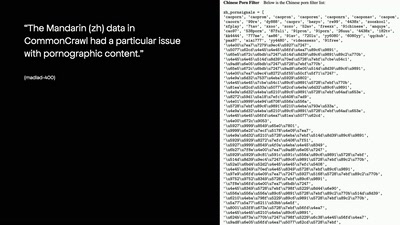
when datasets are scaled up to the volume of (partial) internet, together with the idea that scale will average out the noise, large dataset builders came up with a human-not-in-the-loop, cheaper-than-cheap-labor method to clean the datasets: heuristic filtering. Heuristics in this context are basically a set of rules came up by the engineers with their imagination and estimation to work best for their perspective of “cleaning”. Most datasets use heuristics adopted from existing ones, then add some extra filtering rules for specific characteristics of the datasets. I would like to invite you to have a taste together of these silent, anonymous yet upheld estimations and not-guaranteed rationalities in current sociotechnical artifacts, and on for whom these estimations are good-enough, as it will soon be part our technological infrastructures. In 1980s, non-white women’s body size data was categorized as dirty data when establishing the first women's sizing system in US. Now in the age of GPT, what is considered as dirty data and how are they removed from massive training materials? Datasets nowadays for training large models have been expanded to the volume of (partial) internet, with the idea of “scale averages out noise”, these datasets were scaled up by scrabbling whatever available data on the internet for free then “cleaned” with a human-not-in-the-loop, cheaper-than-cheap-labor method: heuristic filtering. Heuristics in this context are basically a set of rules came up by the engineers with their imagination and estimation that are “good enough” to remove “dirty data” of their perspective, not guaranteed to be optimal, perfect, or rational. The talk will show some intriguing patterns of “dirty data” from 23 extraction-based datasets, like how NSFW gradually equals to NSFTM (not safe for training model), and reflect on these silent, anonymous yet upheld estimations and not-guaranteed rationalities in current sociotechnical artifacts, and ask for whom these estimations are good-enough, as it will soon be part our technological infrastructures. Licensed to the public under http://creativecommons.org/licenses/by/4.0 about this event: https://events.ccc.de/congress/2025/hub/event/detail/a-media-almost-archaeology-on-data-that-is-too-dirty-for-ai
What this episode covers
when datasets are scaled up to the volume of (partial) internet, together with the idea that scale will average out the noise, large dataset builders came up with a human-not-in-the-loop, cheaper-than-cheap-labor method to clean the datasets: heuristic filtering. Heuristics in this context are basically a set of rules came up by the engineers with their imagination and estimation to work best for their perspective of “cleaning”. Most datasets use heuristics adopted from existing ones, then add some extra filtering rules for specific characteristics of the datasets. I would like to invite you to have a taste together of these silent, anonymous yet upheld estimations and not-guaranteed rationalities in current sociotechnical artifacts, and on for whom these estimations are good-enough, as it will soon be part our technological infrastructures. In 1980s, non-white women’s body size data was categorized as dirty data when establishing the first women's sizing system in US. Now in the age of GPT, what is considered as dirty data and how are they removed from massive training materials? Datasets nowadays for training large models have been expanded to the volume of (partial) internet, with the idea of “scale averages out noise”, these datasets were scaled up by scrabbling whatever available data on the internet for free then “cleaned” with a human-not-in-the-loop, cheaper-than-cheap-labor method: heuristic filtering. Heuristics in this context are basically a set of rules came up by the engineers with their imagination and estimation that are “good enough” to remove “dirty data” of their perspective, not guaranteed to be optimal, perfect, or rational. The talk will show some intriguing patterns of “dirty data” from 23 extraction-based datasets, like how NSFW gradually equals to NSFTM (not safe for training model), and reflect on these silent, anonymous yet upheld estimations and not-guaranteed rationalities in current sociotechnical artifacts, and ask for whom these estimations are good-enough, as it will soon be part our technological infrastructures. Licensed to the public under http://creativecommons.org/licenses/by/4.0 about this event: https://events.ccc.de/congress/2025/hub/event/detail/a-media-almost-archaeology-on-data-that-is-too-dirty-for-ai
NOW PLAYING
a media-almost-archaeology on data that is too dirty for "AI" (39c3)
No transcript for this episode yet
Similar Episodes
No similar episodes found.