EPISODE · Mar 10, 2026 · 10 MIN
E048_vLLM_-_Inferencia_rápida,_memoria_eficiente
from BIMPRAXIS
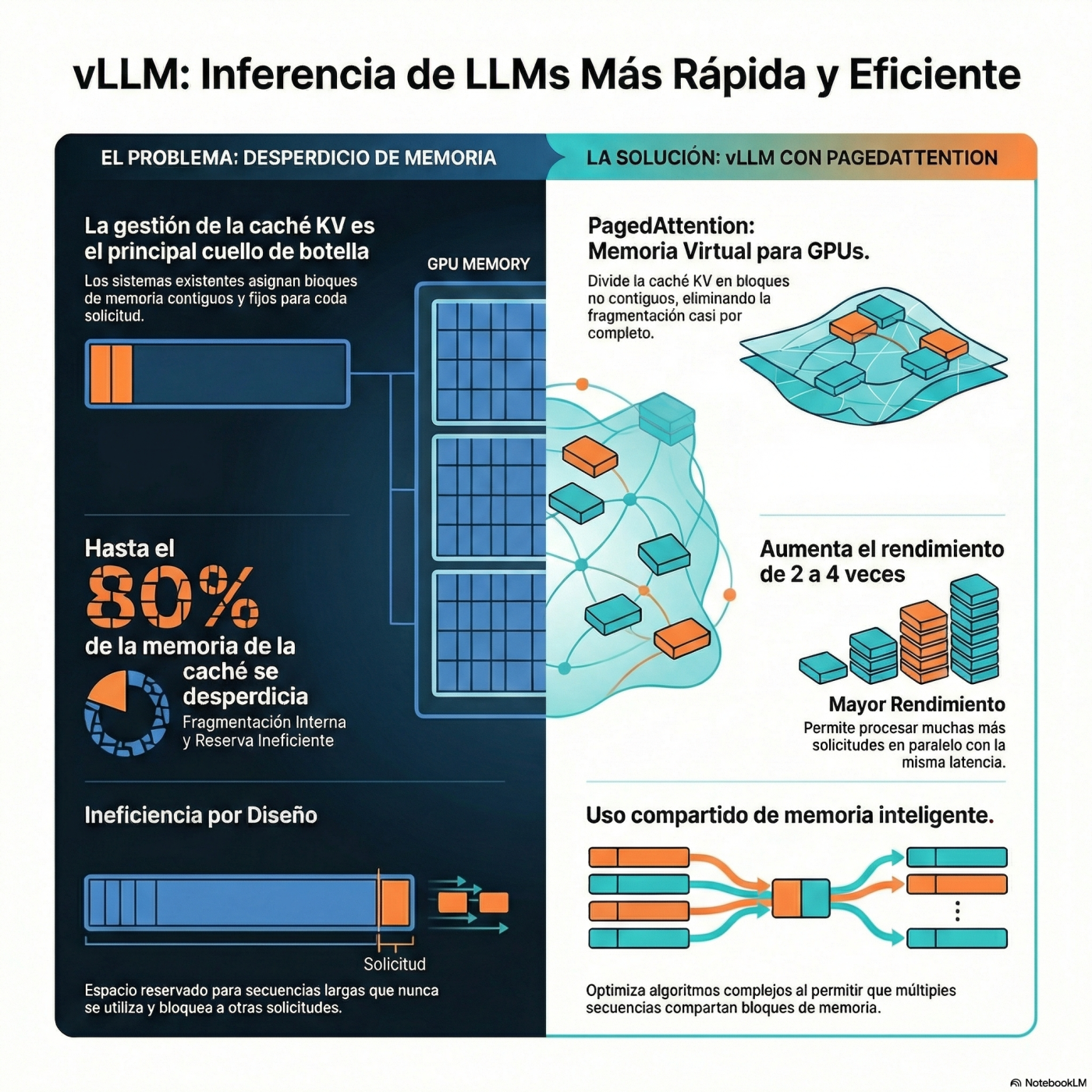
Analizamos VLLM, la herramienta open source que revoluciona la inferencia de Grandes Modelos de Lenguaje (LLMs) al solucionar el principal cuello de botella: la ineficiencia de la memoria GPU. Exploramos cómo su innovadora arquitectura Paged Attention, inspirada en la paginación de sistemas operativos, elimina la fragmentación de la caché KV, logrando reutilización dinámica y ahorros masivos. Descubra por qué VLLM consigue hasta cuatro veces más rendimiento (throughput) que sistemas previos, facilitando optimizaciones de memoria (como copy-on-write) que son cruciales para el futuro diseño de hardware de inteligencia artificial.
NOW PLAYING
E048_vLLM_-_Inferencia_rápida,_memoria_eficiente
No transcript for this episode yet
Similar Episodes
No similar episodes found.
Similar Podcasts
No similar podcasts found.