EPISODE · Mar 20, 2025 · 17 MIN
LLM Concepts Explained: Sampling, Fine-tuning, Sharding, LoRA
from Build Wiz AI Show · host Build Wiz AI
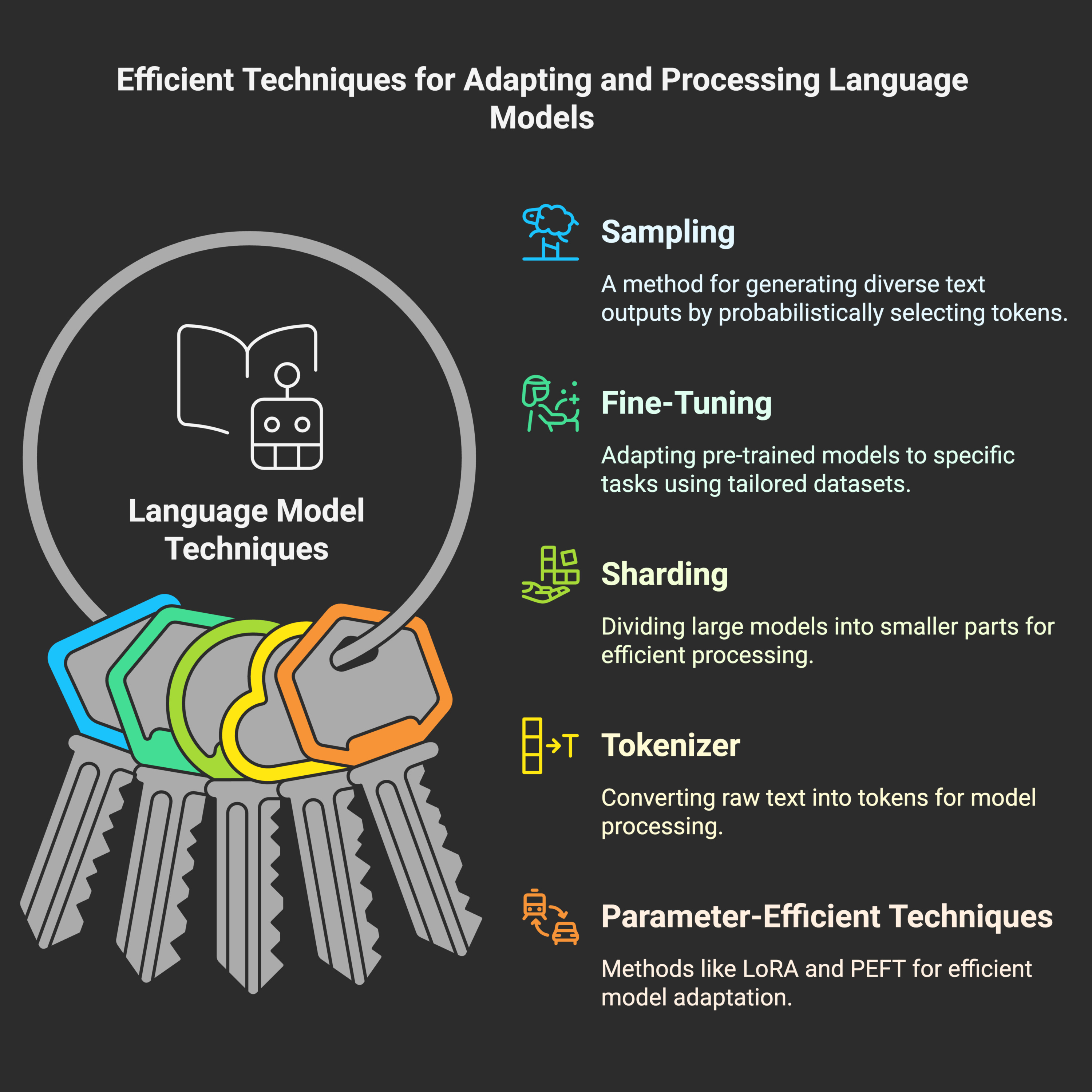
Several key concepts and techniques essential for working with large language models (LLMs). It begins by explaining sampling, the probabilistic method for generating diverse text, and contrasts it with fine-tuning, which adapts pre-trained models for specific tasks. The text then discusses sharding, a method for distributing large models, and the role of a tokenizer in preparing text for processing. Furthermore, it covers parameter-efficient fine-tuning methods like LoRA and general PEFT, which allow for efficient model adaptation, and concludes by explaining checkpoints as mechanisms for saving and resuming training progress.
What this episode covers
Several key concepts and techniques essential for working with large language models (LLMs). It begins by explaining sampling, the probabilistic method for generating diverse text, and contrasts it with fine-tuning, which adapts pre-trained models for specific tasks. The text then discusses sharding, a method for distributing large models, and the role of a tokenizer in preparing text for processing. Furthermore, it covers parameter-efficient fine-tuning methods like LoRA and general PEFT, which allow for efficient model adaptation, and concludes by explaining checkpoints as mechanisms for saving and resuming training progress.
NOW PLAYING
LLM Concepts Explained: Sampling, Fine-tuning, Sharding, LoRA
No transcript for this episode yet
Similar Episodes
No similar episodes found.