EPISODE · Mar 4, 2025 · 38 MIN
LLM Post-Training: Reasoning, Reinforcement Learning, and Scaling
from Build Wiz AI Show · host Build Wiz AI
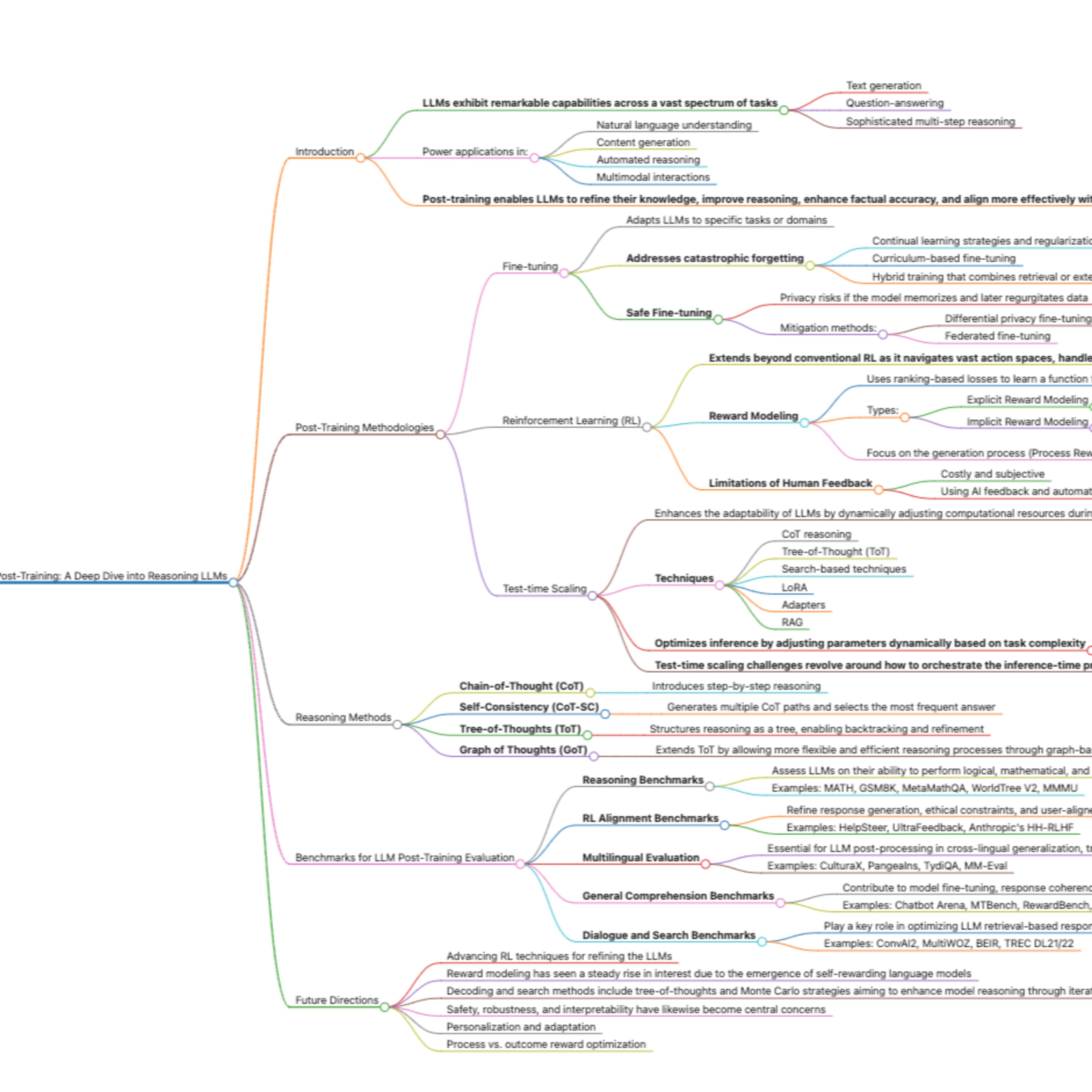
This podcast presents a comprehensive survey of post-training techniques for Large Language Models (LLMs), focusing on methodologies that refine these models beyond their initial pre-training. The key post-training strategies explored include fine-tuning, reinforcement learning (RL), and test-time scaling, which are critical for improving reasoning, accuracy, and alignment with user intentions. It examines various RL techniques such as Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO) in LLMs. The survey also investigates benchmarks and evaluation methods for assessing LLM performance across different domains, discussing challenges such as catastrophic forgetting and reward hacking. The document concludes by outlining future research directions, emphasizing hybrid approaches that combine multiple optimization strategies for enhanced LLM capabilities and efficient deployment. The aim is to guide the optimization of LLMs for real-world applications by consolidating recent research and addressing remaining challenges.
What this episode covers
This podcast presents a comprehensive survey of post-training techniques for Large Language Models (LLMs), focusing on methodologies that refine these models beyond their initial pre-training. The key post-training strategies explored include fine-tuning, reinforcement learning (RL), and test-time scaling, which are critical for improving reasoning, accuracy, and alignment with user intentions. It examines various RL techniques such as Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO) in LLMs. The survey also investigates benchmarks and evaluation methods for assessing LLM performance across different domains, discussing challenges such as catastrophic forgetting and reward hacking. The document concludes by outlining future research directions, emphasizing hybrid approaches that combine multiple optimization strategies for enhanced LLM capabilities and efficient deployment. The aim is to guide the optimization of LLMs for real-world applications by consolidating recent research and addressing remaining challenges.
NOW PLAYING
LLM Post-Training: Reasoning, Reinforcement Learning, and Scaling
No transcript for this episode yet
Similar Episodes
No similar episodes found.