EPISODE · Mar 17, 2026 · 23 MIN
Simple Recipe Works: Vision-Language-Action Models are Natural Continual Learners with Reinforcement Learning
from Best AI papers explained · host Enoch H. Kang
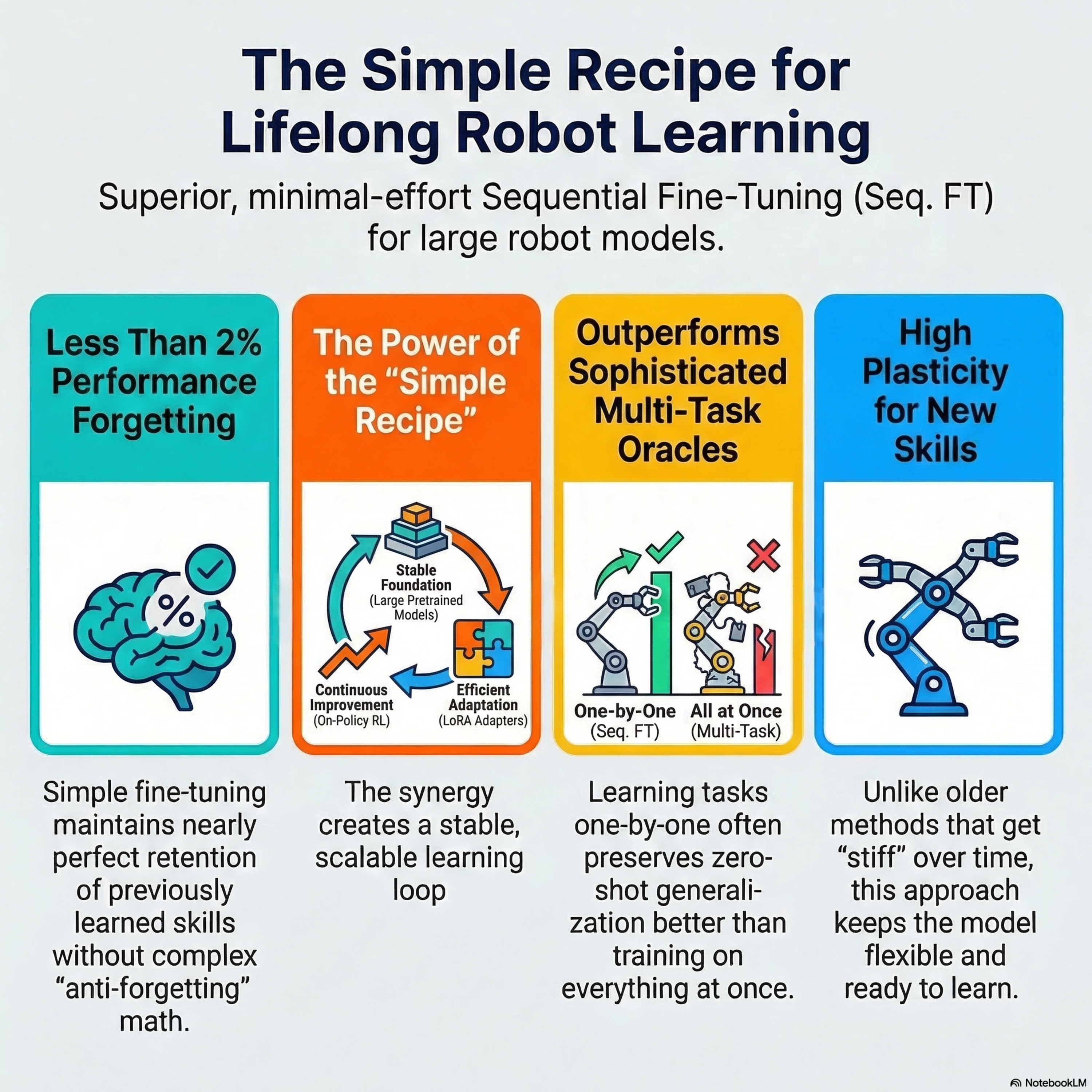
This paper explores Continual Reinforcement Learning (CRL) for large Vision-Language-Action (VLA) models, focusing on how these agents adapt to new tasks without losing prior knowledge. While traditional machine learning often suffers from catastrophic forgetting during sequential training, this research demonstrates that a simple Sequential Fine-Tuning approach remains remarkably effective. By combining pre-trained VLAs, on-policy reinforcement learning, and Low-Rank Adaptation (LoRA), the researchers found that models maintain high plasticity and strong zero-shot generalization. Their systematic study across multiple benchmarks reveals that this basic recipe often outperforms more complex, specialized CRL strategies. Ultimately, the source positions parameter-efficient fine-tuning as a scalable and stable foundation for developing lifelong embodied intelligence in robotic agents.
NOW PLAYING
Simple Recipe Works: Vision-Language-Action Models are Natural Continual Learners with Reinforcement Learning
No transcript for this episode yet
Similar Episodes
Mar 31, 2026 ·54m
Mar 27, 2026 ·14m
Mar 24, 2026 ·42m
Mar 20, 2026 ·42m
Mar 17, 2026 ·41m
Mar 13, 2026 ·44m