EPISODE · Sep 25, 2025 · 12 MIN
Here's How ShareChat Scaled Their ML Feature Store 1000X Without Scaling the Database
from Data Science Tech Brief By HackerNoon · host HackerNoon
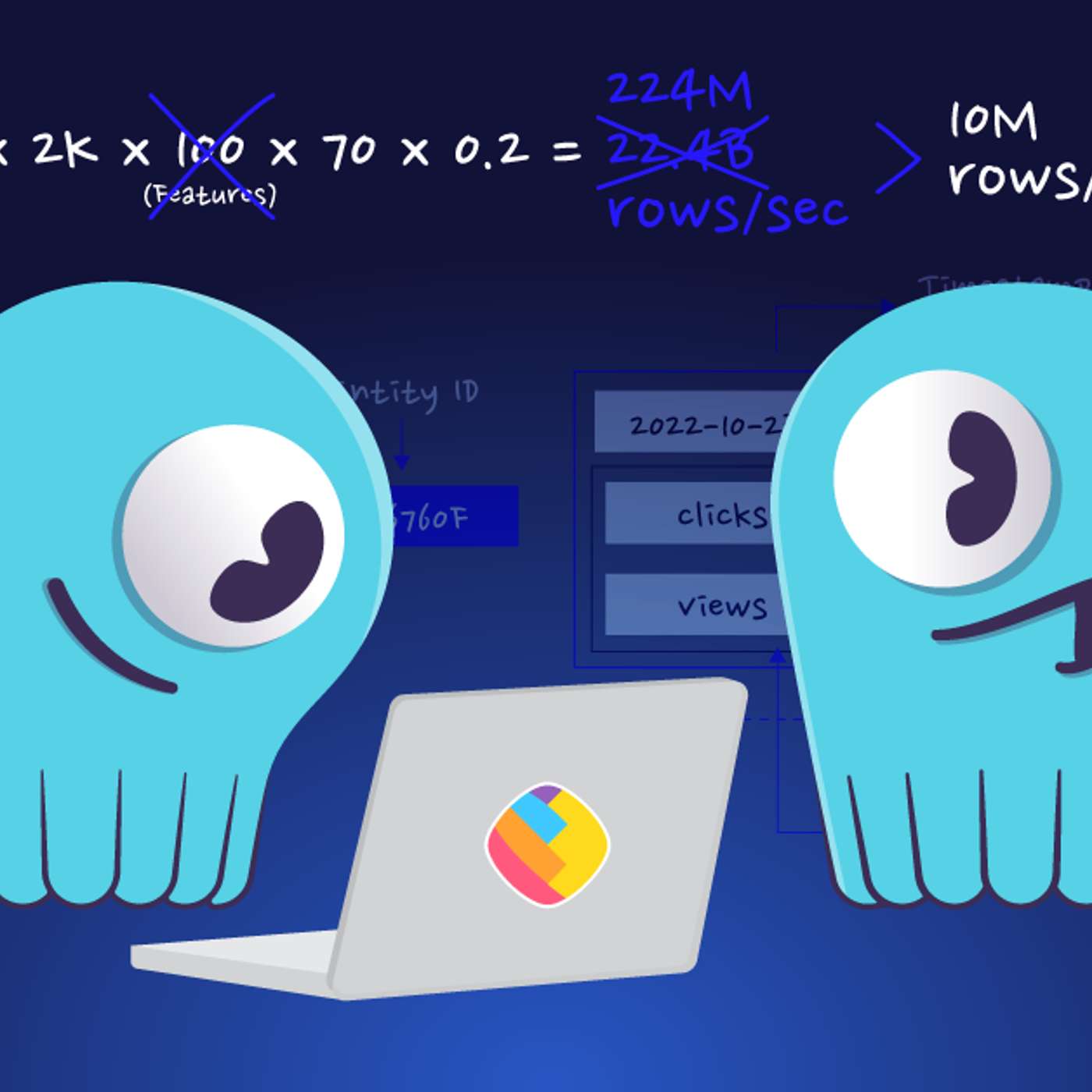
This story was originally published on HackerNoon at: https://hackernoon.com/heres-how-sharechat-scaled-their-ml-feature-store-1000x-without-scaling-the-database. How ShareChat scaled its ML feature store to 1B features/sec on ScyllaDB, achieving 1000X performance without scaling the database. Check more stories related to data-science at: https://hackernoon.com/c/data-science. You can also check exclusive content about #sharechat-ml-feature-store, #scylladb-scaling-case-study, #ml-feature-store-optimization, #sharechat-moj, #low-latency-ml-infrastructure, #scylladb-database-optimization, #p99-conf-sharechat-talk, #good-company, and more. This story was written by: @scylladb. Learn more about this writer by checking @scylladb's about page, and for more stories, please visit hackernoon.com. ShareChat scaled its ML feature store from failure at 1M features/sec to 1B features/sec using ScyllaDB optimizations, caching hacks, and relentless tuning. By rethinking schemas, tiling, and caching strategies, engineers avoided scaling the database, cut latency, and boosted cache hit rates—proving performance engineering beats brute-force scaling.
What this episode covers
This story was originally published on HackerNoon at: https://hackernoon.com/heres-how-sharechat-scaled-their-ml-feature-store-1000x-without-scaling-the-database. How ShareChat scaled its ML feature store to 1B features/sec on ScyllaDB, achieving 1000X performance without scaling the database. Check more stories related to data-science at: https://hackernoon.com/c/data-science. You can also check exclusive content about #sharechat-ml-feature-store, #scylladb-scaling-case-study, #ml-feature-store-optimization, #sharechat-moj, #low-latency-ml-infrastructure, #scylladb-database-optimization, #p99-conf-sharechat-talk, #good-company, and more. This story was written by: @scylladb. Learn more about this writer by checking @scylladb's about page, and for more stories, please visit hackernoon.com. ShareChat scaled its ML feature store from failure at 1M features/sec to 1B features/sec using ScyllaDB optimizations, caching hacks, and relentless tuning. By rethinking schemas, tiling, and caching strategies, engineers avoided scaling the database, cut latency, and boosted cache hit rates—proving performance engineering beats brute-force scaling.
NOW PLAYING
Here's How ShareChat Scaled Their ML Feature Store 1000X Without Scaling the Database
No transcript for this episode yet
Similar Episodes
Mar 26, 2026 ·1m
Jan 2, 2026 ·47m
Dec 21, 2025 ·46m