EPISODE · Jun 2, 2026 · 35 MIN
What Production-Grade RAG Evaluation Should Look Like
from Tech Stories Tech Brief By HackerNoon · host HackerNoon
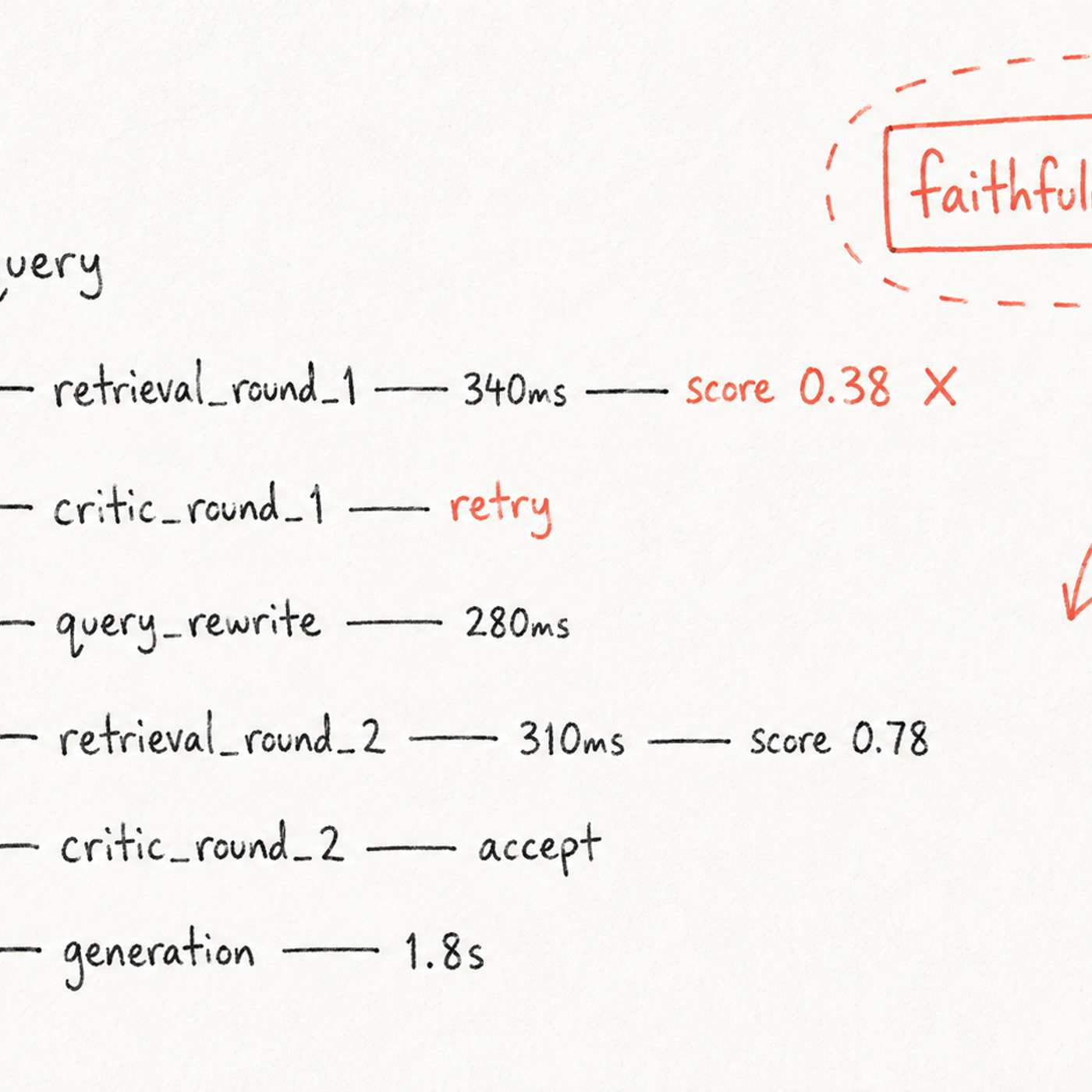
This story was originally published on HackerNoon at: https://hackernoon.com/what-production-grade-rag-evaluation-should-look-like. Learn how to evaluate agentic RAG systems using RAGAS, LangSmith, Langfuse, critic scores, retrieval behavior, latency, and cost. Check more stories related to tech-stories at: https://hackernoon.com/c/tech-stories. You can also check exclusive content about #agentic-rag, #ai-evaluation, #ai-observability, #retrieval-evaluation, #llm-as-a-judge, #rag-faithfulness-scores, #corrective-rag, #hackernoon-top-story, and more. This story was written by: @tnawaz. Learn more about this writer by checking @tnawaz's about page, and for more stories, please visit hackernoon.com. This article argues that evaluating agentic RAG systems requires far more than a single faithfulness score. It explores a production-focused evaluation stack built around RAGAS component metrics, node-level observability with LangSmith and Langfuse, critic scoring, retrieval-round analysis, latency and cost monitoring, and carefully curated evaluation datasets. The central thesis is that modern RAG systems fail in many ways that end-to-end metrics alone cannot detect.
What this episode covers
This story was originally published on HackerNoon at: https://hackernoon.com/what-production-grade-rag-evaluation-should-look-like. Learn how to evaluate agentic RAG systems using RAGAS, LangSmith, Langfuse, critic scores, retrieval behavior, latency, and cost. Check more stories related to tech-stories at: https://hackernoon.com/c/tech-stories. You can also check exclusive content about #agentic-rag, #ai-evaluation, #ai-observability, #retrieval-evaluation, #llm-as-a-judge, #rag-faithfulness-scores, #corrective-rag, #hackernoon-top-story, and more. This story was written by: @tnawaz. Learn more about this writer by checking @tnawaz's about page, and for more stories, please visit hackernoon.com. This article argues that evaluating agentic RAG systems requires far more than a single faithfulness score. It explores a production-focused evaluation stack built around RAGAS component metrics, node-level observability with LangSmith and Langfuse, critic scoring, retrieval-round analysis, latency and cost monitoring, and carefully curated evaluation datasets. The central thesis is that modern RAG systems fail in many ways that end-to-end metrics alone cannot detect.
NOW PLAYING
What Production-Grade RAG Evaluation Should Look Like
No transcript for this episode yet
Similar Episodes
Mar 26, 2026 ·1m
Jan 2, 2026 ·47m
Dec 21, 2025 ·46m